That's good news, IRV is a vast improvement over first-past-the-post. Except it is not the best system. It is too complicated -- enough that the UK's tentative to switch to IRV failed, in part because the pro camp couldn't explain it --, it has some trouble spots, and a simpler system performs better.
Check out this fantastic visualization of the differences between the different voting systems. IRV, like first-past-the-post, will sometimes elect someone nobody really wants.
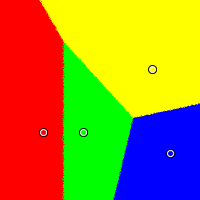 | 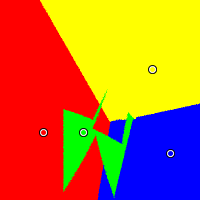 |
| Approval Voting | Instant Runoff Voting |
In the images, the dots are candidates, and the colored regions around the dot label the range of pooling results which leads to that candidate winning. Under IRV (right-most image), the red, the yellow and the blue candidates all intrude on pooling space that ought to belong to the green candidate.
A better alternative is approval voting: people vote for as many candidates as they want, then the candidates with the most votes wins. It is simpler at the pooling box -- no need to tediously order the candidates -- and vastly simpler to explain.
Here's how things went when I found myself describing these two voting systems (at different times, in different working groups):
A better alternative is approval voting: people vote for as many candidates as they want, then the candidates with the most votes wins. It is simpler at the pooling box -- no need to tediously order the candidates -- and vastly simpler to explain.
Here's how things went when I found myself describing these two voting systems (at different times, in different working groups):
Approval Voting
-- Vote for however many candidates you want. You can vote for one, for two, for some of them, or for all of them. However you want. The person with the most votes wins.
-- Ok.
Instant Runoff Voting
-- Don't worry what IRV means, just list your three favorites candidates. Spot 1 is for your most-favorite candidate (don't be confused, it doesn't mean 'Spot 1 receives 1, points Spot 3 receives 3 points.') When all the votes are in, your vote will go to your #1 candidates. If s/he doesn't win, s/he's out of the race, then we count again, but your vote now goes to your #2 candidates. And so forth, until there is only one candidate left. That person is the winner.
-- What do you mean "And so forth?"
-- I mean it's an algorithm and we had a programmer code it into a computer because the old people who volunteer at poling places sometime don't understand it.
-- confused look. I don't understand. Can you explain it again?
That's why I would rather advocate for approval voting. IRV is near impossible to explain to a non-algorithmically-inclined mind. Its opaque name echoes its complicated procedure. And it for all its trouble, it has worse mathematical properties than approval voting.